
We’ve all been watching the amazing progress in AI applied to huge datasets. Better yet, those of us not tracking billions of photos or restaurant reviews have not been left out: transfer learning techniques are making it “easy” to improve specialized models with data gathered for more general tasks. And, thanks to frameworks like PyTorch, applied libraries like fast.ai, and the accessibility of massively parallel hardware through companies like FloydHub, the methods are within the reach of small teams or even individual devs.
Our favorite example illustrating the above is ULMFiT, where Jeremy Howard and Sebastian Ruder at fast.ai show how to accurately classify movie reviews with just a few hundred labeled examples — and a model trained on a giant corpus of general English text.

Fast.ai, however, had one trick up their sleeve besides a working knowledge of English and a handful of labeled reviews. They had a mountain of _domain-specific text:_ 100,000 sample reviews, demonstrating the difference between plain English and movie-critic-ese. That got us thinking: just how much domain data is enough to bridge the gap between a few training examples and a generic language model?
It’s not an idle question. Frame helps companies of all sizes label, rate, and otherwise make sense of their customer conversations on channels like Zendesk, Intercom, and Slack. We can confidently state: there’s a big gap between “we hold few enough conversations we can review them by hand” and “we have enough data to train a model from scratch”. What can a growing customer success operation with do with just a few dozen labels and a few thousand relevant conversations?
The answer, it turns out, is a quite a bit! In this post we’re going to use the same movie review dataset to show transfer learning can make a huge difference even when you’re just beginning to collect data in your domain. We’ll review how transfer learning can aide language analysis, present our experiment, and finally show why even companies with scaled datasets should care!
### Transfer What?
In case you’re tuning in from outside the deep learning community, let’s do a quick refresher. _Deep neural networks_ are the technique behind many recent AI headlines — especially advances in perceptual tasks such as understanding images, audio, or written language. For our purposes, the most important thing to understand about deep nets is that they are made up of _layers_ (that’s the “deep” part), each of which transforms its input into a new representation that’s closer to the answer the network has been trained to find.
A common complaint with deep learning is that we don’t always know what’s happening in those middle layers… but often they’re designed to have clear, interpretable roles! For example, many language models utilize _embedding_ layers that transform individual words or small phrases to a coordinate system that puts similar meanings close together. As an example, this might help a translation AI apply its experience with the word “great” when it runs into a phrase using the word “illustrious”. Helpful, since you don’t see the word “illustrious” in as many contexts!
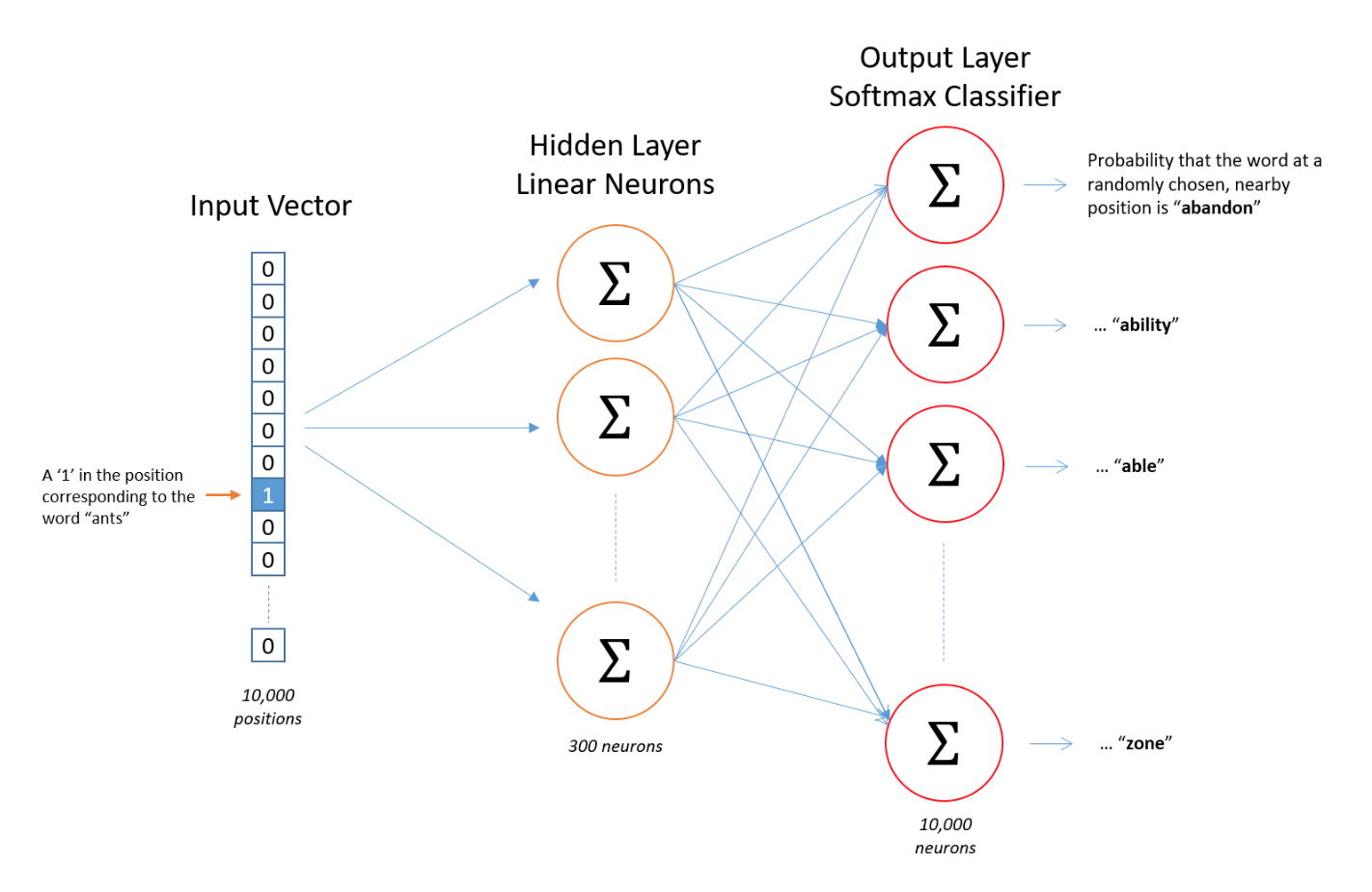 via the very accessible embedding tutorial from Chris McCormack
Now things get interesting: a layer that “knows” that “illustrious = great” isn’t just good for translation — it could help when learning to estimate sentiment, cluster different viewpoints, or much more. That’s _transfer learning_ , where (part of) a model learned for one task makes it easier to pick up another. In fact, this particular example has become so popular that improving general-purpose language models has become a field in itself!
via the very accessible embedding tutorial from Chris McCormack
Now things get interesting: a layer that “knows” that “illustrious = great” isn’t just good for translation — it could help when learning to estimate sentiment, cluster different viewpoints, or much more. That’s _transfer learning_ , where (part of) a model learned for one task makes it easier to pick up another. In fact, this particular example has become so popular that improving general-purpose language models has become a field in itself!
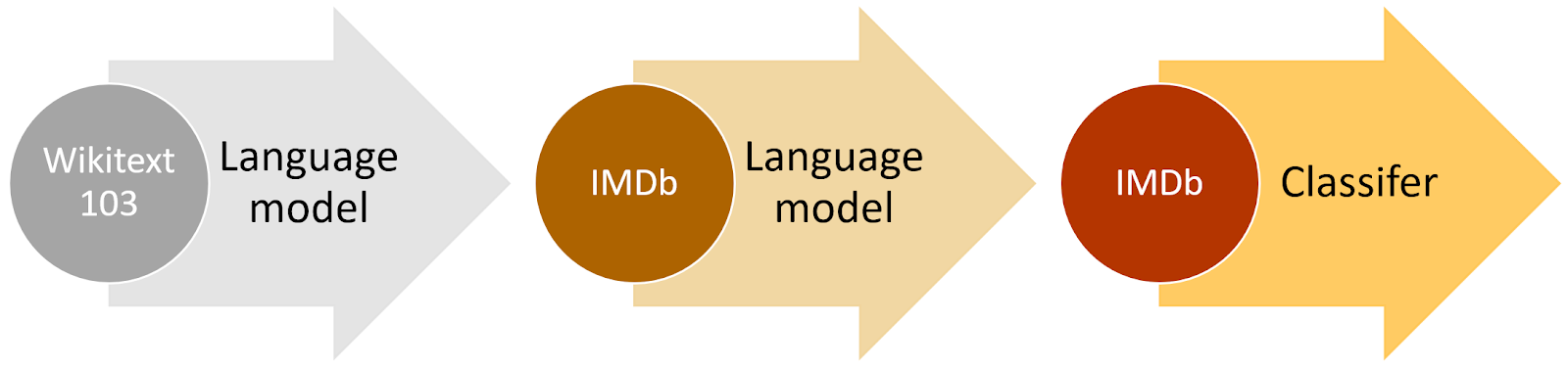 via fast.ai
Transfer learning isn’t just good for moving between tasks; it can help us specialize a general model to work better in a specific environment. For example, a general-English sentiment model might be a decent place to start predicting movie reviews, but might not know that a “taut, tense thriller” is considered a good thing.
That’s where Jeremy and Sebastian Rudder’s Universal Language Model Fine-Tuning for Text Classification (ULMFiT) comes in. They refined a general language model with 100,000 IMDB reviews. Even though only a few hundred were labeled, the rest could help their AI learn that reviewers often substitute “taut, tense” with “illustrious” — or just “great” — bridging the gap to our labeled data. The results were impressive: 94% classification accuracy with just 500 labeled examples.
### How Much (Unlabeled Data) isEnough?
ULMFiT shows a terrific proof of concept for NLP shops to adapt their models to work more effectively with smaller datasets. For Frame, we work with teams across a few different functions (success, support, and sales) and those teams are found within companies that span a huge spectrum of industry verticals and business maturity. From a data perspective that means we see conversational datasets that are highly contextual to a partner in the language they use and vary dramatically in size — both are situations of which would benefit from what has been demonstrated by ULMFiT.
For this research we focus on answering the following:
If I have a small, fixed budget for labeled examples, how much _unlabeled_ domain-specific data do I have to collect to make effective use of transfer learning?
We answered the above with an experiment that pairs with fast.ai’s like this: they used a large, fixed pool of domain data and varied the number of labeled examples to show how the model improved. We held the number of labeled examples constant and varied the amount of additional _unlabeled_ domain examples. More formally, our experiment consists of
via fast.ai
Transfer learning isn’t just good for moving between tasks; it can help us specialize a general model to work better in a specific environment. For example, a general-English sentiment model might be a decent place to start predicting movie reviews, but might not know that a “taut, tense thriller” is considered a good thing.
That’s where Jeremy and Sebastian Rudder’s Universal Language Model Fine-Tuning for Text Classification (ULMFiT) comes in. They refined a general language model with 100,000 IMDB reviews. Even though only a few hundred were labeled, the rest could help their AI learn that reviewers often substitute “taut, tense” with “illustrious” — or just “great” — bridging the gap to our labeled data. The results were impressive: 94% classification accuracy with just 500 labeled examples.
### How Much (Unlabeled Data) isEnough?
ULMFiT shows a terrific proof of concept for NLP shops to adapt their models to work more effectively with smaller datasets. For Frame, we work with teams across a few different functions (success, support, and sales) and those teams are found within companies that span a huge spectrum of industry verticals and business maturity. From a data perspective that means we see conversational datasets that are highly contextual to a partner in the language they use and vary dramatically in size — both are situations of which would benefit from what has been demonstrated by ULMFiT.
For this research we focus on answering the following:
If I have a small, fixed budget for labeled examples, how much _unlabeled_ domain-specific data do I have to collect to make effective use of transfer learning?
We answered the above with an experiment that pairs with fast.ai’s like this: they used a large, fixed pool of domain data and varied the number of labeled examples to show how the model improved. We held the number of labeled examples constant and varied the amount of additional _unlabeled_ domain examples. More formally, our experiment consists of
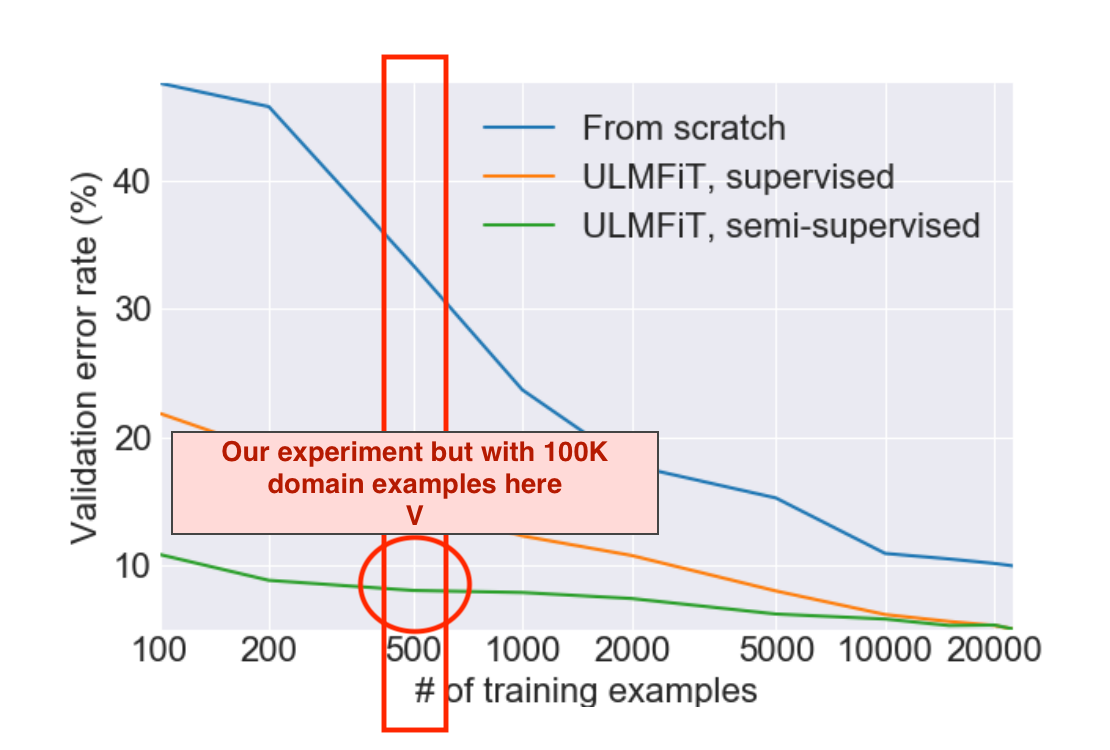 Our research in the context of the results from the original ULMFiT paperabove
For language modeling, we vary the amount of domain data available to three alternative language models feeding into the language task:
Our research in the context of the results from the original ULMFiT paperabove
For language modeling, we vary the amount of domain data available to three alternative language models feeding into the language task:
via the very accessible embedding tutorial from Chris McCormack
Now things get interesting: a layer that “knows” that “illustrious = great” isn’t just good for translation — it could help when learning to estimate sentiment, cluster different viewpoints, or much more. That’s _transfer learning_ , where (part of) a model learned for one task makes it easier to pick up another. In fact, this particular example has become so popular that improving general-purpose language models has become a field in itself!
via fast.ai
Transfer learning isn’t just good for moving between tasks; it can help us specialize a general model to work better in a specific environment. For example, a general-English sentiment model might be a decent place to start predicting movie reviews, but might not know that a “taut, tense thriller” is considered a good thing.
That’s where Jeremy and Sebastian Rudder’s Universal Language Model Fine-Tuning for Text Classification (ULMFiT) comes in. They refined a general language model with 100,000 IMDB reviews. Even though only a few hundred were labeled, the rest could help their AI learn that reviewers often substitute “taut, tense” with “illustrious” — or just “great” — bridging the gap to our labeled data. The results were impressive: 94% classification accuracy with just 500 labeled examples.
### How Much (Unlabeled Data) isEnough?
ULMFiT shows a terrific proof of concept for NLP shops to adapt their models to work more effectively with smaller datasets. For Frame, we work with teams across a few different functions (success, support, and sales) and those teams are found within companies that span a huge spectrum of industry verticals and business maturity. From a data perspective that means we see conversational datasets that are highly contextual to a partner in the language they use and vary dramatically in size — both are situations of which would benefit from what has been demonstrated by ULMFiT.
For this research we focus on answering the following:
If I have a small, fixed budget for labeled examples, how much _unlabeled_ domain-specific data do I have to collect to make effective use of transfer learning?
We answered the above with an experiment that pairs with fast.ai’s like this: they used a large, fixed pool of domain data and varied the number of labeled examples to show how the model improved. We held the number of labeled examples constant and varied the amount of additional _unlabeled_ domain examples. More formally, our experiment consists of
- Language Modeling (variant)
- Language Task (invariant)
Our research in the context of the results from the original ULMFiT paperabove
For language modeling, we vary the amount of domain data available to three alternative language models feeding into the language task:
- **ULM Only** : this is using Wikitext103 pre-trained English language model
- **Domain Only** : a domain based language model trained only on IMDB data
- **ULM + Domain** : the ULMFiT model
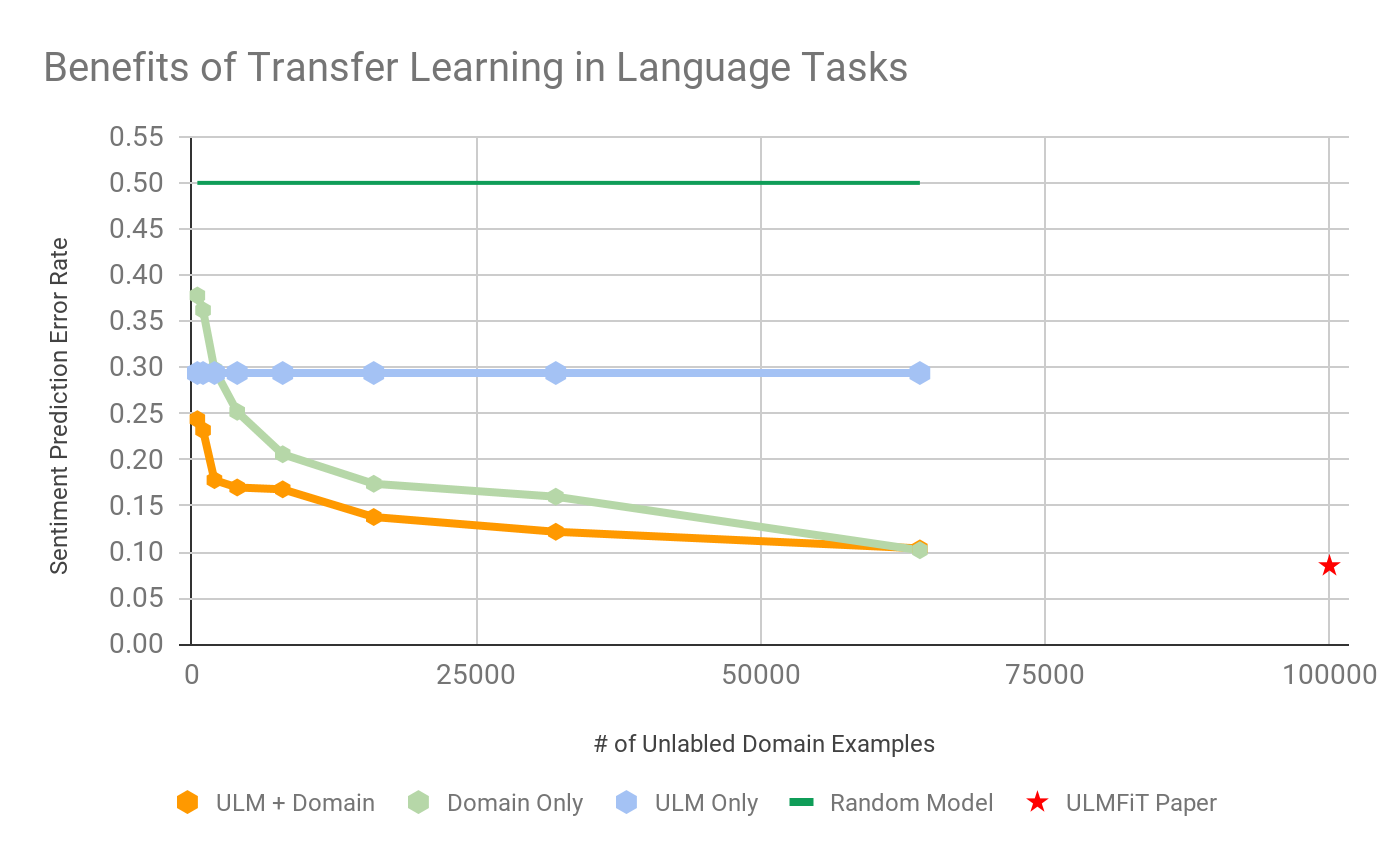
What we see above tells a clear story:
- Considering both broad language structures from the ULM and unlabeled domain text always leads to a major improvement — even when domain text is minimal.
- We can get 75% of the performance UMLFiT reported with 33% of the domain data.
- **Amazingly, ULM + 2,000 domain examples reached nearly 85% language task prediction accuracy.**

